
Puttin’a Prior on it
This is a post based on Julia Silge’s post on estimating a beta distribution using Billboard’s Year-End Hot 100 song lyrics from 1958 to 2014. As you see from my lame title, my post will not be nearly as witty or well-designed as hers, but you may find this extension of her work interesting. I conducted this analysis of the Bayesian Blues methods/data for a few reasons: 1) I had picked up a few ideas on using Stan for density estimation and wanted to try them out, 3) I am always on the lookout to practice with dplyr/tidverse; 3) I really enjoy the beta distribution and its intuition (see @drob’s SE post); and 4) Silge’s analysis provided a really cool method and interesting data, of which she was kind to share both (Silge on GH). The data, code, and a commented full markdown of my analysis are posted on GitHub.
“Singing the Bayesian Beginner Blues“
As noted, the analysis goals and data in this post are directly based on Julia Silge’s post entitled Singing the Bayesian Beginner Blues. That post used the Empirical Bayes method for beta parameter point estimation and establishing the uncertainty around measurements of U.S. state names mentioned within a large database of song lyrics (courtesy of Kaylin Walker). Silge’s post first approximates the parameters of a beta distribution from her data (the Empirical part) and then use those parameters and Bayes Theorem to approximate a rate for each state if it were derived from that beta distribution. Finally, Silge derived a posterior distribution for each state’s rate; from which that uncertainty around the rate was visualized as the 95% Credible Interval. This is a really cool approached and is demonstrated with great visualizations. While reading it, I was inspired to figure this out in Stan and started messing with some code.
The primary differences in this analysis include:
- Is zero inflated to include states not mentioned in lyrics
- Incorporates mentions of cities with >= 100k population aggregated to their state and compares to analysis without city counts
- Utilizes Hamiltonian Monte Carlo via
rstanto estimate parameters, propagated uncertainty, and predict state mention values given priors, data, and likelihood.
Estimating Beta Parameters with Stan
The approach in this post uses Stan, a probabilistic modeling language, to achieve the beta parameter estimation, propagate uncertainty, and predict a posterior distribution for each state, as well as the entire population of song-lyric-mention-rates. Stan is a modernized version of BUGS and JAGS that is cross-platform and endlessly flexible for estimating a huge range of models. The Stan website is very informative and there are a number of videos of presentations that helped me get my head around the concepts. The very basics of Stan are an No U-Turns (NUTS) Adaptive Hamiltonian Monte Carlo (HMC) sampling engine and a language with which to declare your model. The code for the model gets compiled into C++, the model is sampled with HMC, and the posterior is computed with samples returned to the user as a convenient R object.

That above image is from utilized in one of Benjamin Goodrich’s presentations (and also used Bob Carpenter in one of these videos) [Edit: Bob Carpenter created this image and it has been used by the Stan team in various presentations] to illustrate the efficiency in the HMC NUTS algorithm. Compared to Metropolis and Gibbs, HMC NUTS explores the true posterior (right-most panel) way more effectively and efficiently. There is no contest there.

On a conceptual level, two primary differences between the Stan approach and the Empirical Bayes (EB) approach is that Stan (and other MCMC style samplers) integrates over distributions where the EB uses point estimates. With distributions, we can propagate uncertainty through all of the steps of the modeling sequence. Secondly, the full Bayesian approach uses priors to regularize the parameter estimates given the data and model. The end result is control over the amount of regularization based on choice of priors and the ability to understand uncertainty because every parameter has a distribution of its plausible values.
In my previous post on estimating Pokemon CP, I did a very similar task by estimating a beta distribution density with JAGS. The approach here with Stan is more sound than the JAGS approach as HMC is a better sampler than the Gibbs sampler of JAGS, and that I incorporate the prediction of new values within the model. In the previous example, I used a range of beta parameters extracted from the posterior to re-model the predictions. Doing this as a generated quantities in Stan more accurately propagates the uncertainty.
The Model: State Mentions in Song Lyrics as a Beta
The beta distribution is thought of as a succession of binomial trials of successes and failures. As such, it covers the domain of a distribution of probabilities of success. To think of it as a rate of success is to conceptualize the problem here as: How many song mentions per unit of population?
- successes = how many songs successfully mention a state by name
- attempts = a state’s population in units of 100k people (or 1,000,000 in Silge)
There is a bit of a dis-junction in intuition here as the success and attempts are on two completely different scales and it is not limited to the domain of [0,1]; there is no upper bound on the number of songs that mention a state relative to population. An example of a more intuitively sound beta is Robinsons’s batting average whereas counter to the song mentions example, you cannot have more hits than at bats so it remains between [0,1]. However despite this disjunction, there is still ground for the state based interpretation; it is a very useful and convenient distribution, and Silge showed that it fits the observed data pretty darn well. So we go with it! [note: I modeled these data a few other potential distributions, and beta ‘won’ in terms of log likelihood.]
The models follows as such:

predictions for states are drawn from:
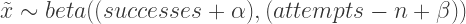
So the likelihood that we are estimating is that the observed state-mention-rates are distributed from a 


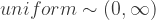

Here the half-normal is used to constrain both 

Data: Fetch, Clean, Tokenize & Join
The steps do this follow very closely to Silge’s approach with some minor modifications. I will not spell out the code in great details here, but check out the markdown here to see all the details step by step. There are three datasets used here, 1) the Billboard Hot-1oo song lyrics (Kaylin Walker’s GH); 2) 2014 state populations from the Census using the acs packages (API Key required!); and 3) names of U.S. cities with populations of greater than 100k (on my GH). The data ingestion downloads or directly loads the .csv files, melts, mutates, and cleans a few issues.
stategeo <- geo.make(state = "*")
popfetch <- acs.fetch(geography = stategeo,
endyear = 2014,
span = 5,
table.number = "B01003",
col.names = "pretty")
## song lyrics
lyrics_url <- "https://raw.githubusercontent.com/walkerkq/musiclyrics/master/billboard_lyrics_1964-2015.csv"
save_lyrics_loc <- "~/Documents/R_Local/Put_a_prior_on_it-Blog_post/data/billboard_lyrics_1964-2015.csv"
# download.file(lyrics_url, save_lyrics_loc)
song_lyrics <- read_csv(save_lyrics_loc)
cities_dat_loc <- "~/Documents/R_Local/Put_a_prior_on_it-Blog_post/data/cities_over_100k_pop.csv"
state_abbrev_loc <- "~/Documents/R_Local/Put_a_prior_on_it-Blog_post/data/state_abbrev.csv"
state_abbrev <- read_csv(state_abbrev_loc)
The real magic of the data prep is the creation of bi-grams from the song lyrics dataset. This could be a very arduous process, or we could use the tidytext package and unnest_tokens function to do it all for us. Wrapped in some dplyr, we get this:
# extract desired info from acs data
pop_df <- tbl_df(melt(estimate(popfetch))) %>%
mutate(name = as.character(Var1),
state_name = tolower(Var1),
pop2014 = value) %>%
dplyr::select(name, state_name, pop2014) %>%
filter(state_name != "puerto rico") %>%
left_join(state_abbrev)
# clean in city names
cities <- read_csv(cities_dat_loc) %>%
mutate(city = gsub("\x96", "-", city),
city_name = tolower(city),
state_name = tolower(state))
# extract and tidy lyrics from songs data
tidy_lyrics <- bind_rows(song_lyrics %>%
unnest_tokens(lyric, Lyrics),
song_lyrics %>%
unnest_tokens(lyric, Lyrics,
token = "ngrams", n = 2))
Both rigth_join and inner_join joins are used to link the song lyrics to both state and city names. The right_join is used for state names so that we can retain the state names that do not have any match in the lyric tokens. However, inner_join is used for the cities because I do not want to retain a whole bunch of cities that are not mentioned.
# join and retain songs whether or not they are in the lyrics
tidy_lyrics_state_zeros <- right_join(tidy_lyrics, pop_df, by = c("lyric" = "state_name")) %>%
distinct(Song, Artist, lyric, .keep_all = TRUE) %>%
mutate(cnt = ifelse(is.na(Source), 0, 1)) %>%
filter(lyric != "district of columbia") %>%
dplyr::rename(state_name = lyric)
tidy_lyrics_state <- filter(tidy_lyrics_state_zeros, cnt > 0)
## count the states up
zero_rate <- 0.0000001 # beta hates zeros
# group, summarise, and calculate rate per 100k population
state_counts_zeros <- tidy_lyrics_state_zeros %>%
group_by(state_name) %>%
dplyr::summarise(n = sum(cnt)) %>% # sum(cnt)
left_join(pop_df, by = c("state_name" = "state_name")) %>%
mutate(rate = (n / (pop2014 / 100000)) + zero_rate) %>%
arrange(desc(n))
Finally, the data are summarized to come up with counts by state and cities; that are then aggregated back to the state in which they are located.
### Cities
## join cities together - inner_join b/c I don't care about cities with zero mentions (right_join otherwise)
tidy_lyrics_city <- inner_join(tidy_lyrics, cities, by = c("lyric" = "city_name")) %>%
distinct(Song, Artist, lyric, .keep_all = TRUE) %>%
filter(!city %in% c("Surprise", "Hollywood",
"District of Columbia", "Jackson",
"Independence")) %>%
mutate(cnt = ifelse(is.na(Source), 0, 1)) %>%
dplyr::rename(city_name = lyric)
# count cities mentions. No need for a rate; not of use now
city_counts <- tidy_lyrics_city %>%
group_by(city_name) %>%
dplyr::summarise(n = sum(cnt)) %>%
arrange(desc(n))
# count of states that host the cities mentioned
city_state_counts <- tidy_lyrics_city %>%
group_by(state_name) %>%
dplyr::summarise(n = sum(cnt)) %>%
arrange(desc(n))
state_city_counts_zeros <- left_join(state_counts_zeros, city_state_counts, by = "state_name") %>%
dplyr::rename(n_state = n.x, n_city = n.y) %>%
mutate(n_city = ifelse(is.na(n_city), 0, n_city),
n_city_state = n_state + n_city,
city_state_rate = (n_city_state / (pop2014 / 100000)) + zero_rate)
# same as above, but no states with zero mentioned by city or state
state_city_counts <- filter(state_city_counts_zeros, n_city_state > zero_rate)
Translating Model to Stan Code
There are lots of great places to read about Stan and how to code it. Start with the docs and videos on the Stan website. I can’t get into too much detail here because Stan and probabilistic programming in general can be approached from so many angles and levels that no blog post can do it justice (and frankly, my understanding is pretty surficial!). I will however comment on the code to help illustrate how it matches the model above.

Stan models are coded to reflect the way one would think about a statistical model in the abstract. Statistically, a model can be thought of as the data, the parameters, the “model” represented as a likelihood function, and optionally the values or predictions generated from the model. In the Stan code, these model elements are split into blocks of code statements, of which only the parameters and model blocks are required to build a model. This PDF is a good place to see the structure of a Stan model.
This analysis used the beta density estimating model posed above in two different models:
- as an optimization problem to derive parameters via penalized Maximum Likelihood Estimation (MLE); and
- as a joint probability model sampled with HMC with the addition of a
generated quantitiescode block for making predictions.
Optimizing MLE for Point Estimation
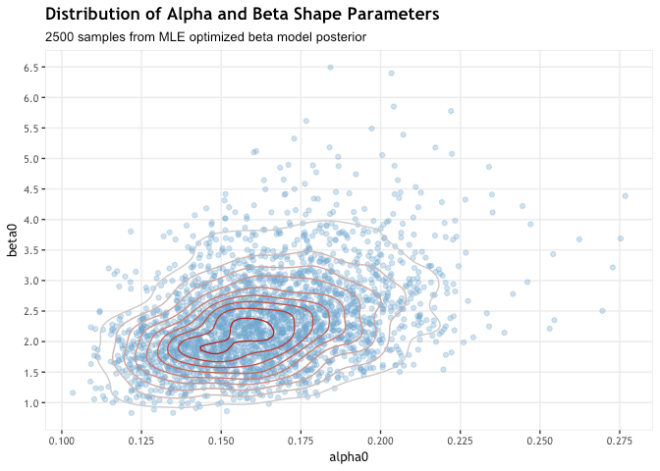
For the first model, we used the rstan optimizing() function to employ an MLE optimization algorithm called Limited memory Broyden–Fletcher–Goldfarb–Shannon or LBFGS (BFGS and quasi-Newtonian optimization are also available). The result is a point estimate of the joint posterior along with a log likelihood estimate, and optionally the Hessian matrix and n parameters estimates from the posterior. The pros of this approach over the full bayes model is that it is very fast, quite accurate, and delivers posterior samples that can be used for estimating sensitivity and uncertainty. Cons are that it really helps to know decent initialization values for your parameters, that you are limited to a more simple model specification, and finally it is only point estimates. Here is the model and code to run it. As in the output below, the estimated parameter values from the optimization are alpha0 ≅ 0.1615 and beta0 ≅ 2.2172
opt_chr1 <- "
data {
int<lower=0> N;
real x[N];
}
parameters {
real<lower = 0> alpha0;
real<lower = 0> beta0;
}
model {
alpha0 ~ normal(0, 1);
beta0 ~ normal(0, 10);
//target += beta_lpdf(x | alpha0, beta0); // same as below
x ~ beta(alpha0, beta0);
}
# initialize parameter values (based on knowledge or fitdist results)
init_list <- list(alpha0 = 0.1, beta0 = 1)
# compile model (~ 10 to 15 seconds)
opt_mod1 <- stan_model(model_code = opt_chr1)
# optimize data given model
opt1 <- optimizing(object = opt_mod1, as_vector = FALSE,
data = list(x = state_counts_zeros$rate,
N = length(state_counts_zeros$rate)),
hessian = TRUE,
draws = 2500)
Sampling with Stan HMC for Posterior Prediction
The second way in which the beta model is used here is as a full joint probability model coded in Stan and sampled with NUTS HMC to derive a full posterior density. From this density, prediction are made and compared to the empirical observations (posterior predictive check). The code of the Stan model differs from the above only in that there is a new generated quantities block added on to the end and that it is executed with the stan() function. Within this block the vector x_tilde is defined and used to store the predicted mentioned-in-lyrics rate for each of the 50 states. These predictions are obtained with the beta distribution, state populations, observed song mentions, and the distribution of beta parameters estimated by HMC. As such, the distribution of estimated beta parameters (not just point estimates) are used to model the uncertainty of the mention rate estimate and regularize each state towards a population mean. States with higher rates, but fewer “attempts” (lower population in our case) are shrunk more than states with lots of observations. Essentially, this operationalizes Sagan’s axiom that Extraordinary claims require extraordinary evidence.
// previous Stan model code ...
} generated quantities {
vector[M] x_tilde;
for (n in 1:M)
x_tilde[n] = beta_rng((new_success[n] + alpha0),
(new_attempts[n] - new_success[n] + beta0));
}
new_success = state_counts_zeros$n
new_attempts = (state_counts_zeros$pop2014)/100000
model_dat1_pred <- list(x = state_counts_zeros$rate,
N = length(state_counts_zeros$rate),
new_success = new_success,
new_attempts = new_attempts,
M = length(new_success))
fit1_pred <- stan(model_code = model_string1_pred, data = model_dat1_pred, iter = 10000, chains = 4, warmup=2500)
The same model was also run for the dataset that contains the sum of state mentions and city mentions of cities with >= 100k population.
Model Results
Once fit, there are a number of ways to evaluate the model. This includes both evaluating the convergence of the HMC sampling chains, as well as the model result/parameters themselves to identify any pathologies or misspecification. Neither of these lend a particularly satisfying answer for problems of sufficient complexity. However, there are a few tools to help check our sanity. The first is that the model actually compiled and ran. If you get a stanfit object, you at least have a compiled model. During the fit process, convergence diagnostics are printed t0 the terminal along with warnings and errors. The most common warning is that there are rejected proposals in the Markov chain. If the number of rejected proposals is low, you are probably fine; Stan is pretty sensitive and expresses its feelings freely. If a major issue arises, it will error out and will not return a fit object. Although, a model the compiles and fits can still be completely wrong :). Plotting chains to see proper chain mixing and convergence (referred to at times as fuzzy caterpillars) via rstan::traceplot , posterior predictive checks, and fitting simulated data to recover known parameters are all good approaches to model checking.

In the model stanfit object summary, a series of columns are presented that will help identify potential issues in your fit. Using some dplyr action below, we can get a tidier version of that summary table [Note that there is a broom package stanfit object tidier, but I rolled my own here]. What this gives us is the parameter name, posterior mean, posterior standard deviation, ends of the 95% Credible Interval (CI), the effective number of samples used as n_eff, and the Rhat statistic. This table speaks to both aspects of model evaluation; the parameter values and distribution indicate whether the model could find a decent distribution for the random variables, and the n_eff and Rhat indicate model convergence. While the metrics for parameter distributions (mean, sd, and 95% CI) are pretty self illustrating, n_eff and Rhat are likely not.
Briefly, n_eff is the number of effective samples used in the post-warmup phase of the sampling process. In this case, we used four (4) chains of 10,000 samples each with a warm-up of 2,500 samples each. Combining the chains and removing the warm-up samples, leaves us with 30,000 potential effective samples per parameter; in many cases we achieved all of those are close to it. As this is a simple problem to fit, that is not unexpected to have so many effective samples, but in more complex problems n_eff will not likely account for 100% of your samples; you want it to be relatively high. The Rhat is a statistic to measure the convergence of the 4 chains. Essentially, if they converge, Rhat = 1 , but if there are convergence problems it may not. Be careful with Rhat as it does not scale linearly. I have not found great guidance on this, but in my experience, values of 1.2, or 1.3 are bad and, a value of 1.5 and I would be very worried, and by 2 all hell has broken loose.
fit1_pred_summary <- data.frame(summary(fit1_pred)[["summary"]]) %>%
rownames_to_column() %>%
mutate(Parameter = c("alpha0", "beta0",
as.character(state_counts_zeros$name), "lp__")) %>%
dplyr::select(Parameter, mean, sd, X2.5., X97.5., n_eff, Rhat) %>%
dplyr::rename(Mean = mean,
SD = sd,
`2.5%` = X2.5.,
`97.5%` = X97.5.)
kable(fit1_pred_summary, digits = 3)
This code produces the table below that depicts the parameter values and convergence statistics for the two shape parameters and for each state [I truncated that table after a few states]. The mean posterior values of alpha0 ≅ 0.167 and beta0 ≅ 2.492 are slightly different from the MLE optimization method, but not wildly so. Don’t forget, the values here are an integration of weakly informative priors and data, whereas the optimization has no specified priors (or perhaps infinitely wide uniform priors). The SD and 95% CI give you a sense of the distribution of each parameter. Rhat and n_eff all look good.
An important observation here is that both New York and Mississippi have similar posterior mean mention rates, 0.308 and 0.313 respectively, but the 95% CI for New York is much smaller than for Mississippi, [0.247 – 0.373] and [0.168 – 0.482] respectively. This is because the larger population of New York leads to more certainty that the high mention-rate is an accurate reflection of the process. Whereas the lower population of Mississippi may lead to an artificially high mention-rate and therefore more uncertainty as to its true value.
| Parameter | Mean | SD | 2.5% | 97.5% | n_eff | Rhat |
|---|---|---|---|---|---|---|
| alpha0 | 0.167 | 0.024 | 0.123 | 0.218 | 19325.35 | 1 |
| beta0 | 2.492 | 0.731 | 1.293 | 4.183 | 19034.59 | 1 |
| New York | 0.308 | 0.032 | 0.247 | 0.373 | 30000.00 | 1 |
| California | 0.089 | 0.015 | 0.063 | 0.120 | 30000.00 | 1 |
| Georgia | 0.218 | 0.041 | 0.143 | 0.304 | 30000.00 | 1 |
| Tennessee | 0.211 | 0.050 | 0.121 | 0.314 | 30000.00 | 1 |
| Texas | 0.050 | 0.013 | 0.027 | 0.079 | 29378.00 | 1 |
| Alabama | 0.239 | 0.059 | 0.134 | 0.364 | 29778.71 | 1 |
| Mississippi | 0.313 | 0.081 | 0.168 | 0.482 | 30000.00 | 1 |
| Kentucky | 0.155 | 0.052 | 0.067 | 0.271 | 29964.90 | 1 |
| Hawaii | 0.373 | 0.117 | 0.164 | 0.613 | 29831.56 | 1 |
| Illinois | 0.047 | 0.018 | 0.018 | 0.089 | 30000.00 | 1 |
| … | … | … | … | … | … | … |
The same process was completed for the state + city mentions dataset. The results will be compared below.
new_success_SC <- state_city_counts_zeros$n_city_state
new_attempts_SC <- (state_city_counts_zeros$pop2014)/100000
model_SC_pred <- list(x = state_city_counts_zeros$city_state_rate,
N = length(state_city_counts_zeros$city_state_rate),
new_success = new_success_SC,
new_attempts = new_attempts_SC,
M = length(new_success_SC))
Visualize Results
To visualize these results, i’ll employ the plots that Julia Silge designed for her post. In doing so, I thought it would add continuity between these posts and methods. I changed the axis text and titles, but this really nice looking plot designs are fully attributed to Silge (I hope she doesn’t mind!).
The first plot is a bit of a posterior predictive check for our model to make sure our specification and parameterization can generate new data that resembles our observed data. As in Gelman and Hill (2007, p. 158), “simulating replicated data under the fitted model and then comparing these to the observed data”. This S.O. post has a good little discussion. In this case, the observed mention rates for each state are compared against the mean of the posterior predictive distribution for each state. This distribution is derived from the generated quantities block of the Stan model. As we can see from the results below, most observations fall on the identity line. However, a few at the top deviate a bit; namely Hawaii and Mississippi (Montana is also a bit off line further down the scale). These represent states that have a high mention rate (HI = 0.431), but are predicted to have a lower mention rate due to their low populations (HI = 1,392,704) relative to mentions (HI = 6). This is in opposition to the anchor of this model, New York with 61 mentions for 19,594,330 for a rate of 0.311 per 100k people. This is the evidence for shrinkage of our estimates.
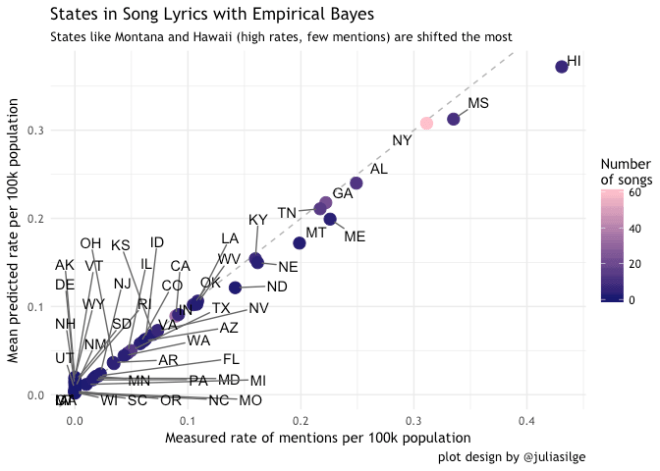
The second plot, also designed by Silge, illustrates the same comparison between mean of the posterior prediction for each state and the observed value. In this case, the states are arranged by mention rate in descending order and 95% Credible Interval (as defined by the 0.25 and 0.975 posterior quantiles). See these great posts by David Robinson and Rasmus Bååth on the topic of credible intervals. While Hawaii still has the highest observed mention rate, it also has the highest CI interval and spread between the predicted mean and observed. New York on the other hand has a modest CI and a mean estimate that is very close to the observed.

State + City Mention Rates
The above process was completed for both state counts (as in Silge), but also for state mentions plus the mention of cities of >= 100k population within states. Granted, there are some obvious flaws with this approach, some I controlled for and other not controlled for. For example, the word “Independence” is likely reference outside of the geographic context of the city of Independence, Missouri. The same thing occurs for the word “Jackson”, “Hollywood” (Florida!), and “Surprise”. These city names were removed from the analysis. Here are the same plots with the addition of city counts.
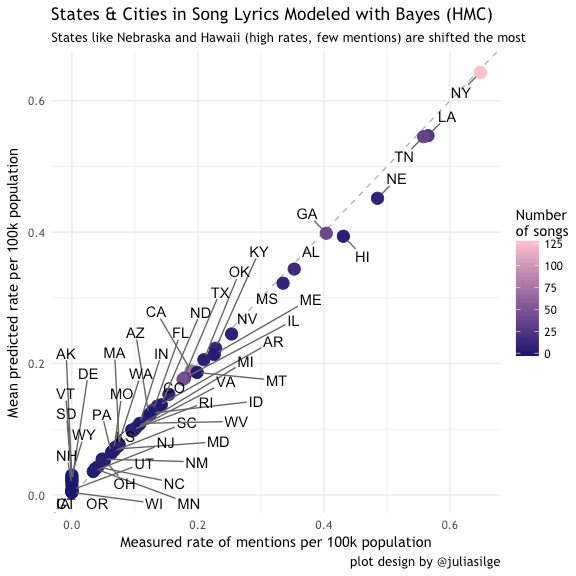

Results
Which model to chose? I think using city and state counts is a bit more coherent with idea of geographic song mentions and perhaps a bit more robust. Using cities and states, New York rises straight to the top of the heap and states like Louisiana and Tennessee climb because if cities like New Orleans and Nashville, respectively.
There are lots of ways to compare which model is “better”, but I am not going to go crazy with it. Log posteriors from the Stan models can be compared, but I do not believe they can be used for inference directly in the form they are reported from the fit object. We could also do things like hold-out samples, k-folds cross-validation (CV), Leave-One-Out CV, or use information criteria such as WAIC [See Gelman] and go down the rabbit hole from there.
Here I take a simple approach and calculate a few metrics based a few things:
- Loss Metrics
- Mean Absolute Error (MAE)
- Root Mean Square Error (RMSE)
- Credible Interval (CI)
- mean width of 95% CI
- Predicted Mentions
- RMSE of expected mentions vs observed mentions
- MAE of the same
These result show that the state counts only model may have the slightest advantage over the states + cities counts, but it is very small. For me, the choice of model would simply be which fits my purpose better; both are pretty decent at estimating the number of mentions. the MAE of expected mentions per state is less than 0.2 of a mention; a pretty minor error in the case where we are trying to fit a distribution to estimate uncertainty. However, if the intention of this model were to predict song mentions on a new state, the average state, or mentions from a different song population (country charts, alternative chart, etc…), the model and interpretation of the errors may be different. Truly, the purpose of this model is to show a method to adapt Julia Silge’s approach using Stan. The beta distribution described these data pretty accurately, but infer at your own risk!
| Model | RMSE rate | MAE rate | Median CI | RMSE mentions | MAE mentions |
|---|---|---|---|---|---|
| States Only | 0.013 | 0.007 | 0.111 | 0.249 | 0.174 |
| City and States | 0.012 | 0.008 | 0.181 | 0.298 | 0.204 |
city_state_error <- state_city_estimates %>%
mutate(rate_error = mean - city_state_rate,
pred_mentions = round(mean * (pop2014/100000),1),
mention_error = n_city_state - pred_mentions,
CI_width = q975 - q025) %>%
dplyr::summarise(RMSE_rate = sqrt(mean(rate_error^2)),
MAE_rate = mean(abs(rate_error)),
mean_CI = mean(CI_width),
RMSE_mentions = sqrt(mean(mention_error^2)),
MAE_mentions = mean(abs(mention_error))) %>%
as.numeric()
state_error <- state_estimates %>%
mutate(rate_error = mean - rate,
pred_mentions = round(mean * (pop2014/100000),1),
mention_error = n - pred_mentions,
CI_width = q975 - q025) %>%
dplyr::summarise(RMSE_rate = sqrt(mean(rate_error^2)),
MAE_rate = mean(abs(rate_error)),
median_CI = median(CI_width),
RMSE_mentions = sqrt(mean(mention_error^2)),
MAE_mentions = mean(abs(mention_error))) %>%
as.numeric()
#print
model_rmse <- data.frame(model = c("States Only", "City and States"),
RMSE_rate = c(state_error[1], city_state_error[1]),
MAE_rate = c(state_error[2], city_state_error[2]),
Median_CI = c(state_error[3], city_state_error[3]),
RMSE_mentions = c(state_error[4], city_state_error[4]),
MAE_mentions = c(state_error[5], city_state_error[5]))
kable(model_rmse, digits = 3)
Thanks!!!!
NOTES:
- If you see any errors or omissions, please contact me at @md_harris
- The code, data, and a more in-depth explanation of the code are in this GitHub repo.
- David Robinson has a great new post on Hierarchical Beta parameterization
- Perhaps a poisson process would be another way to approach this, but again it was for illustrative purposes.
- The musical note banner at the top is Dan Bruno’s version of the Zelda Ocarian tone
- The code for the variations of the beta distribution plot is in the R_scripts folder on my github.
- The Stan logo and ensemble sweep banner are from mc-stan.org
- The nymph riding a caterpillar liner break is illustrated and provided by Trick Slattery

Bob made that plot with the comparison of NUTS to M-H and Gibbs. I stole it from him.
LikeLike
Thanks for the clarification Ben. I put an edit in the text.
LikeLike