[In the last post, I talked about showing various learning algorithms from the perspective of predictions within the “feature space”. Feature space being a perspective of the model that looks at the predictions relative to the variables used in the model, as opposed geographic distribution or individual performance metrics.
I am adding to that post the Gaussian Process (GP) model and a fun animation Or two.

So what’s a GP?
The explanation will differ depending on the domain of the person you ask but essentially a GP is a mathematical construction that uses a multivariate Gaussian distribution to represent an infinite number of functions the describe your data, priors, and covariance. Each data point gets Gaussian distribution and these are all jointly represented as the multivariate Gaussian. The choice of the Gaussian is key to this as it makes the problem tractable based on some very convenient properties of the multivariate Gaussian. When referring to a GP one may be talking about regression, classification, a fully Bayesian method, some form or arbitrary functions, or some other cool stuff I am too dense to understand. That is a broad and overly-simplistic explanation, but I am overly-simplistic and trying to figure it out myself. There is a lot of great material on the web and videos on youtube to learn about GP.
So why use it for archaeology?
GP’s allow for the the estimation of stationary nonlinear continuous functions across an arbitrary dimensional space; so it has that going for it… which is nice. But more to the point, it allows for the selection of a specific likelihood, priors, and a covariance structure (kernel) to create a highly tunable probabilisitic classifier. The examples below use the kernlab::gausspr() function to compute the GP using Laplace approximation with a Gaussian noise kernel. The 


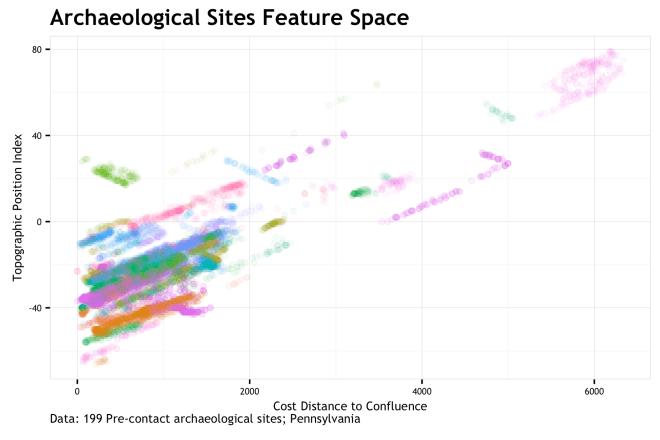
 = cd_conf, anf
= cd_conf, anf  = tpi_250c. cd_conf is a cost distance to the nearest stream confluence with respect to slope and tpi_250c is the topographic position index over a 250 cell neighborhood. If we map
= tpi_250c. cd_conf is a cost distance to the nearest stream confluence with respect to slope and tpi_250c is the topographic position index over a 250 cell neighborhood. If we map  as our {X,Y} coordinates, we end up with…
as our {X,Y} coordinates, we end up with…