
Puttin’a Prior on it
This is a post based on Julia Silge’s post on estimating a beta distribution using Billboard’s Year-End Hot 100 song lyrics from 1958 to 2014. As you see from my lame title, my post will not be nearly as witty or well-designed as hers, but you may find this extension of her work interesting. I conducted this analysis of the Bayesian Blues methods/data for a few reasons: 1) I had picked up a few ideas on using Stan for density estimation and wanted to try them out, 3) I am always on the lookout to practice with dplyr/tidverse; 3) I really enjoy the beta distribution and its intuition (see @drob’s SE post); and 4) Silge’s analysis provided a really cool method and interesting data, of which she was kind to share both (Silge on GH). The data, code, and a commented full markdown of my analysis are posted on GitHub.
“Singing the Bayesian Beginner Blues“
As noted, the analysis goals and data in this post are directly based on Julia Silge’s post entitled Singing the Bayesian Beginner Blues. That post used the Empirical Bayes method for beta parameter point estimation and establishing the uncertainty around measurements of U.S. state names mentioned within a large database of song lyrics (courtesy of Kaylin Walker). Silge’s post first approximates the parameters of a beta distribution from her data (the Empirical part) and then use those parameters and Bayes Theorem to approximate a rate for each state if it were derived from that beta distribution. Finally, Silge derived a posterior distribution for each state’s rate; from which that uncertainty around the rate was visualized as the 95% Credible Interval. This is a really cool approached and is demonstrated with great visualizations. While reading it, I was inspired to figure this out in Stan and started messing with some code.
The primary differences in this analysis include:
- Is zero inflated to include states not mentioned in lyrics
- Incorporates mentions of cities with >= 100k population aggregated to their state and compares to analysis without city counts
- Utilizes Hamiltonian Monte Carlo via
rstanto estimate parameters, propagated uncertainty, and predict state mention values given priors, data, and likelihood.
Estimating Beta Parameters with Stan
The approach in this post uses Stan, a probabilistic modeling language, to achieve the beta parameter estimation, propagate uncertainty, and predict a posterior distribution for each state, as well as the entire population of song-lyric-mention-rates. Stan is a modernized version of BUGS and JAGS that is cross-platform and endlessly flexible for estimating a huge range of models. The Stan website is very informative and there are a number of videos of presentations that helped me get my head around the concepts. The very basics of Stan are an No U-Turns (NUTS) Adaptive Hamiltonian Monte Carlo (HMC) sampling engine and a language with which to declare your model. The code for the model gets compiled into C++, the model is sampled with HMC, and the posterior is computed with samples returned to the user as a convenient R object.

That above image is from utilized in one of Benjamin Goodrich’s presentations (and also used Bob Carpenter in one of these videos) [Edit: Bob Carpenter created this image and it has been used by the Stan team in various presentations] to illustrate the efficiency in the HMC NUTS algorithm. Compared to Metropolis and Gibbs, HMC NUTS explores the true posterior (right-most panel) way more effectively and efficiently. There is no contest there.

On a conceptual level, two primary differences between the Stan approach and the Empirical Bayes (EB) approach is that Stan (and other MCMC style samplers) integrates over distributions where the EB uses point estimates. With distributions, we can propagate uncertainty through all of the steps of the modeling sequence. Secondly, the full Bayesian approach uses priors to regularize the parameter estimates given the data and model. The end result is control over the amount of regularization based on choice of priors and the ability to understand uncertainty because every parameter has a distribution of its plausible values.
In my previous post on estimating Pokemon CP, I did a very similar task by estimating a beta distribution density with JAGS. The approach here with Stan is more sound than the JAGS approach as HMC is a better sampler than the Gibbs sampler of JAGS, and that I incorporate the prediction of new values within the model. In the previous example, I used a range of beta parameters extracted from the posterior to re-model the predictions. Doing this as a generated quantities in Stan more accurately propagates the uncertainty.
The Model: State Mentions in Song Lyrics as a Beta
The beta distribution is thought of as a succession of binomial trials of successes and failures. As such, it covers the domain of a distribution of probabilities of success. To think of it as a rate of success is to conceptualize the problem here as: How many song mentions per unit of population?
- successes = how many songs successfully mention a state by name
- attempts = a state’s population in units of 100k people (or 1,000,000 in Silge)
There is a bit of a dis-junction in intuition here as the success and attempts are on two completely different scales and it is not limited to the domain of [0,1]; there is no upper bound on the number of songs that mention a state relative to population. An example of a more intuitively sound beta is Robinsons’s batting average whereas counter to the song mentions example, you cannot have more hits than at bats so it remains between [0,1]. However despite this disjunction, there is still ground for the state based interpretation; it is a very useful and convenient distribution, and Silge showed that it fits the observed data pretty darn well. So we go with it! [note: I modeled these data a few other potential distributions, and beta ‘won’ in terms of log likelihood.]
The models follows as such:

predictions for states are drawn from:
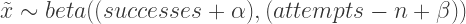
Continue reading “Estimating a Beta Distribution with Stan HMC”
