Quick Way longer then expected post and some code for looking into the estimation of kernel hyperparameters using STAN HMC/MCMC and R. I wanted to drop this work here for safe keeping. Partially for the exercise of thinking it through and writing it down, but also because it my be useful to someone. I wrote a little about GP in a previous post, but my understanding is rather pedestrian, so these explorations help. In general GPs are non-linear regression machines that utilize a kernel to reproject your data into a larger dimensional space in order to represent and better approximate the function we are targeting. Then using a covariance matrix calculated from that kernel, a multivariate Gaussian posterior is derived. The posterior can then be used for all of the great things that Bayesian analysis can do with a posterior.
Read lots more about GP here…. Big thanks to James Keirstead for blogging a bunch of the code that I used under the hood here and thanks to Bob Carpenter (github code) and the Stan team for great software with top-notch documentation.
code:
The R code for all analysis and plots can be found in a gist here, as well as the three Stan model codes, here gp-sim_SE.stan, gp-predict_SE.stan,and GP_estimate_eta_rho_SE.stan

The hyperparameters of topic here are parameters of the kernel within the GP algorithm. As with other algorithms that use kernels, a number of functions can be used based on the type of generative function you are approximating. The most commonly used kernel function for GP (and seemingly Support Vector Machines) is the Squared Exponential (SE), also known as the Radial Basis Function (RBF), Gaussian, or Exponentiated Quadratic function.
The Squared Exponential Kernel
The SE kernel is a negative length scale factor rho (
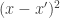

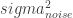
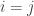
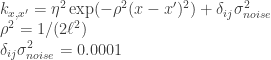
To Fix or to Estimate?
In this post, models are created where 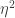

So while the greatest minds in Hamiltonian Monte Carlo chat about it, I am going to just naively work on the Stan code to do these estimations and see where it takes me. Even if fixed with informative priors is the way to go, I at least want to know how to write/execute the model that estimates them. So here we go.
The SE Kernel Prior
The SE kernel is the scale factor 
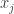
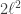
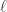

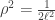
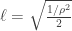
## Simplified form
Sigma[i,j] <- eta_sq * exp(-rho_sq*(x[i] - x[j])^2) +
ifelse(i==j, sigma_sq, 0.0)
## Length parameter == l instead of rho_sq
Sigma[i,j] <- eta_sq * exp(-((x[i] - x[j])^2)/(2*(l^2))) +
ifelse(i==j, sigma_sq, 0.0)
## Intermediate with rho_sq inplace of (2*l^2)
Sigma[i,j] <- eta_sq * exp(-((x[i] - x[j])^2)/(1/rho_sq)) +
ifelse(i==j, sigma_sq, 0.0)
Fortunately, it is simple to go from R to Stan in this instance. The differences are that ifelse() in R is if_else() in Stan and that we have to use the pow() function in Stan over the caret (^) operator in R.
// simplified form
Sigma[i,j] <- eta_sq * exp(-rho_sq*pow(x[i] - x[j],2)) +
if_else(i==j, sigma_sq, 0.0)
// Length parameter == l instead of rho_sq
Sigma[i,j] <- eta_sq * exp(-((pow(x[i] - x[j],2))/(2*pow(l,2)))) +
if_else(i==j, sigma_sq, 0.0)
// Intermediate with rho_sq inplace of (2*l^2)
Sigma[i,j] <- eta_sq * exp(-((pow(x[i] - x[j],2))/(1/rho_sq))) +
if_else(i==j, sigma_sq, 0.0);
When this kernel is computed for a series of x, in this case x = seq(-5, 5, 0.05), we get a 201 x 201 matrix with identical upper and lower triangles. The diagonal where 
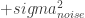

Looking a little further, the 


Put pretty generally (and hand-wavyey) that is how the kernel works. It computes a function based on the distance between 
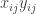



The Gaussian Process
The GP is a Bayesian method and as such, there is a prior, there is data, and there is a posterior that is the prior conditioned on the data. In this example the kernel function and values of 

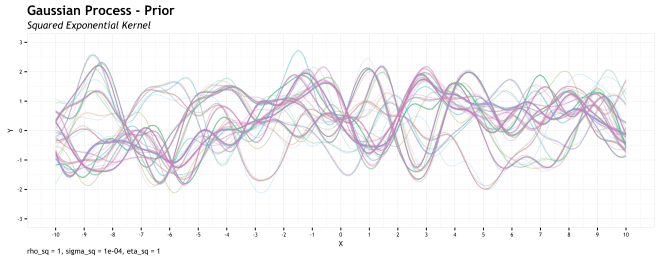
The above plot shows the logical implications of drawing functions from the multivariate Gaussian based on the kernel hyperparameter selection. This is not conditioned on data and therefore represents our prior assumption of the function space from which the data may be generated. Ok, so lets add some data…

Here I have 8 completely arbitrary data points that I made up. The bias behind these is that I wanted a somewhat evenly space set of 

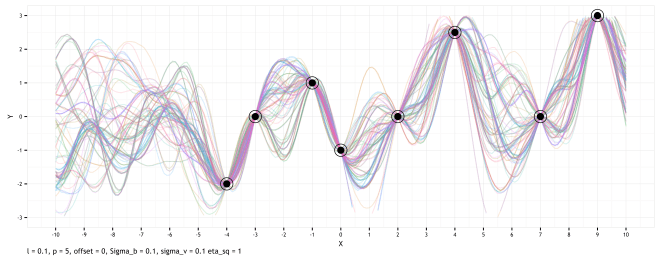
The graphic above shows the outcome of this process; the logical implications of conditioning our prior assumptions (based on kernel hyperparameters) on data. Since we are working under the assumption of noiseless data points (not very realistic), the functions of the posterior are those that pass through the data points. However, between data points, our uncertainty is expressed as variations in the function. To the left of the first data point, the model is pretty uncertain as to what the value of
A more formal specification of the above model is as such:

How the prior effects our model
I went through all this kernel bit and what does it have to do with the GP? Essentially, the hyperparameters within the kernel affect various aspects of the resulting prior functions. On an abstracted level, they guide the kernel into properly encoding our assumptions about the functions into the matrix

This graphic pretty clearly illustrates what varying SE kernel hyperparameters does to the prior. Increasing 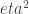

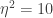

Fitting this range of priors to our 8 data points, and we get the posteriors shown above. The combination of 


Just for fun, I plotted the posteriors (purple) over the priors (orange) to see how they compare.
GP Kernel Hyperparameter Estimation
If you made it this far, you are a champ! So, which is the right set of hyperparameter values? If your prior knowledge or intuition does not give you this answer, you can use sampling to help figure it out. With the stan/HMC/MCMC framework, we can specify the random variables of the model that we want to estimate. As good Bayesians, we are rewarded with a distribution over that random variable and then we can infer from it. In this case, I am interested in estimating both

To visualize the results in a similar manner as before, we must choose values from the resulting distributions of

So, the posterior for the joint hyperparameter estimation is interesting, but what about when they are combined for the range of the distribution? As above, low = 5%, median = 50%, and high = 95%. In the below plot, the left to right diagonal is the same hyperparameter combinations as the above plot. The upper right shows the 95th percentile scale (amplitude) hyperparameter with the 5th percentile inverse length scale parameter. Whereas the lower left shows a low amplitude with short oscillations.

The distribution of these parameters is visualized in the plot below. Note that this is only a single chain simulation with 150 iterations; that will no do for your real world models. However, for getting code off the ground with made up data, it demonstrates the concept. From here, there are many ways to go. Depending on your problem, the length scale might have a very significant meaning and you can do inference on the posterior of that variable. Perhaps you will find that the estimations are way off from what you expect and the you further explore your data. Maybe you find out it is best to fix it because the MAP is right were anticipated and you don’t want to spend CPU cycles on it. Those basic questions are the real crux of modeling and well beyond the scope of this code oriented post.
I hope some of the information here is educational, has some relevance, and is not too riddled with error. I find GPs a really interesting framework for prediction and inference. I have only scratched the surface and will continue to work at them and find applications in my archaeological area of interest. However, these are universal machines and can applied to pretty much any domain. I plan to post again about variations in the kernel and the affects of kernel manipulation, but I will save that for another time.
Any errors in this post are my own dumb fault and will be corrected; please contact me if you see anything. The code for all of these graphics and models is here.
notes:
The R code for all analysis and plots can be found in a gist here, as well as the three Stan model codes, here gp-sim_SE.stan, gp-predict_SE.stan,and GP_estimate_eta_rho_SE.stan
> sessionInfo() R version 3.2.2 (2015-08-14) Platform: x86_64-apple-darwin13.4.0 (64-bit) Running under: OS X 10.10.5 (Yosemite) locale: [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8 attached base packages: [1] stats graphics grDevices utils datasets methods [7] base other attached packages: [1] ggalt_0.3.0.9000 lattice_0.20-33 MASS_7.3-43 [4] viridis_0.3.4 cowplot_0.6.2 matrixcalc_1.0-3 [7] reshape2_1.4.1 plyr_1.8.3 rstan_2.9.0 [10] ggplot2_2.1.0 loaded via a namespace (and not attached): [1] Rcpp_0.12.4 RColorBrewer_1.1-2 base64enc_0.1-3 [4] tools_3.2.2 extrafont_0.17 digest_0.6.9 [7] jsonlite_0.9.19 gtable_0.2.0 DBI_0.3.1 [10] parallel_3.2.2 gridExtra_2.2.1 Rttf2pt1_1.3.3 [13] httr_1.1.0 dplyr_0.4.3 stringr_1.0.0 [16] htmlwidgets_0.6 maps_3.1.0 stats4_3.2.2 [19] grid_3.2.2 inline_0.3.14 R6_2.1.2 [22] plotly_3.4.13 tidyr_0.4.1 extrafontdb_1.0 [25] magrittr_1.5 htmltools_0.3.5 scales_0.4.0 [28] codetools_0.2-14 rsconnect_0.4.1.4 assertthat_0.1 [31] proj4_1.0-8 colorspace_1.2-6 labeling_0.3 [34] KernSmooth_2.23-15 ash_1.0-15 stringi_1.0-1 [37] lazyeval_0.1.10 munsell_0.4.3

Hey thanks for the great blog post. I’ve noticed that your James Keirstead link is broken. Do you know if the website has moved, or if the post is archived elsewhere?
Thanks
LikeLike
Hello Tim, good catch! There is a bit of his work mirrored on R-bloggers: https://www.r-bloggers.com/gaussian-process-regression-with-r/
and this gist: https://gist.github.com/jkeirstead/2312411
Also check out Michael Betancourt’s 3 part series on GP: https://betanalpha.github.io/assets/case_studies/gp_part1/part1.html
Thanks for reading!
LikeLike