“With four parameters I can fit an elephant and with five I can make him wiggle his trunk.” – John von Neumann
This post came about for two reasons:
- I’ve been playing with @drob‘s gganimate package for ggplot2 and it is really fun; and hopefully useful in demonstrating my point.
- Overfitting is arguably the single most important concept to understand in prediction. It should wake you out of a deep sleep at 3am asking yourself, ” Is my model overfit?”
The first point is fun and games, the second is very serious. Fortunately, using gganimate is simple, but unfortunately dealing with overfitting can be very difficult.
![]()
Overfitting is a pretty easy concept; your model fits your data very well, but performed poorly when predicting new data. This happens because your model fit the noise of you data; likely because it is too flexible or complex. If a model employees many degrees of freedom, it is very flexible and can seek out every data point leading to a wiggly line that misses the underlying signal that you are attempting to model. Note that the concept here is part and parcel with the concept of Bias & Variance trade-off, but I’ll sidestep that and save it for another time.
An overfit model will appear to be very accurate when compared to the data used to build (aka “train”) the model. This is because with every additional degree of freedom your error (e.g. Root Mean Square Error [RMSE]) will decrease. The more flexibility, the lower the error; yeah pack it up, we can go home now. Complex models.. FTW!
Hold on tiger… the problem is as flexibility increases the model fits more and more to the noise that is unique to the particular data sample you are training the model on. This particular noise will not likely be present in another sample drawn from the same overall population. Therefore, a model that has low error because it strongly fits the noise of the training data, will have a high rate of error on new data that has different noise. However. not all is lost: the trick is to balance model complexity to achieve optimal error rates considering both data sets and your modeling objective. Let’s see some plots.
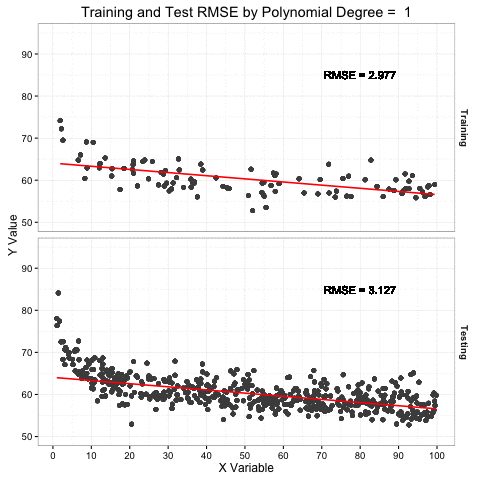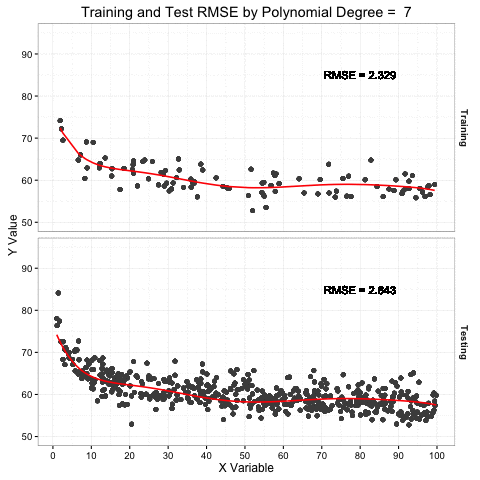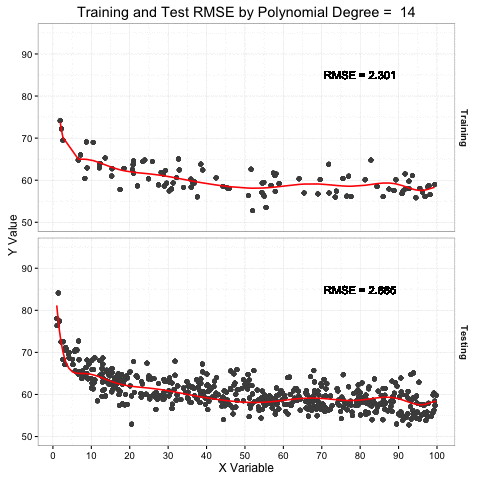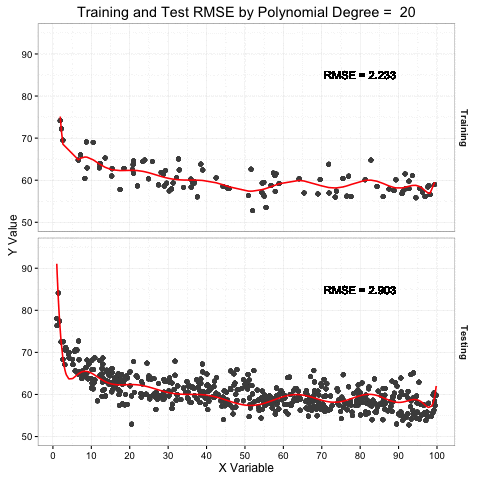
The plot above demonstrates this concept by showing an increasing complex model (red line) fit to the training data sample in the top pane. The bottom pane shows a larger sample of testing data that is more representative of the total target population. The red line in the lower pain is the prediction of the testing data based on the model fit to the training data above.
The key thing to note is the increased flexibility as the model complexity increases (i.e. polynomial degrees) and how it more tightly fits the variation in the training data. At the same time, that model predictions for testing data are much more complex than necessary because the model is anticipating a data set just like the one it trained on. The RMSE of the training set continues to drop as the model becomes more complex, but the testing RMSE only drops to a point and then rises as the model becomes more overfit. An overfit model is a one trick pony. Don’t be a one trick pony.
I prefer a little bit of analogy, so for an archaeological example we can pretend that this data represents something like the y = count of rhyolite flakes and x = count of chert flakes on site within a drainage basin. We observe in our small sample that there tends to be high amounts of rhyolite where there is little chert, but also that even for high amounts of chert there is a pretty consistently moderate amount of rhyolite. Framing it that way, we can see how our small sample holds the general trend of all the unobserved sites in the basin, but if we fit too flexible of a model, we will estimate quantities that are simply the result of our limited sample size.

This is only for one train/test set, so maybe it is just a bad random draw, right? Not really. Simulating this over 100 permutations of this data population show the textbook test/train error curves when aggregated to their mean. The red line for training error will continue to decrease as model complexity increases. It will level out, but it will not increase. On the other hand, the test data error decreases until the population parameters are approximated and then it increases as the model becomes over fit. This clearly depicts the risk in being over confident in a model that has a low training error.
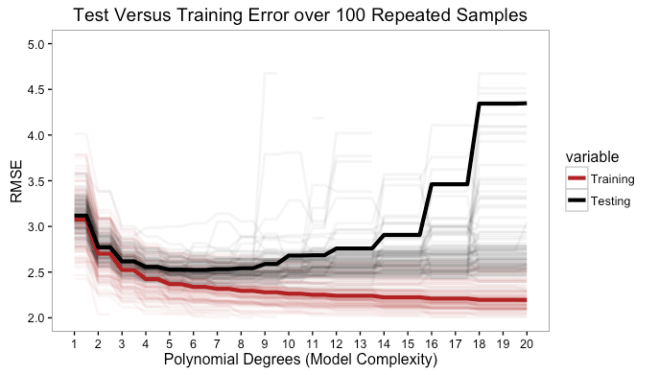
In the graphic above, the degree of model complexity at which both errors are, on average, closest is around a linear fit (1st order) or second degree polynomial, but the point at which the model test error is lowest is around a 5 or 6 degree polynomial. This data was low order polynomial model, so the lower error of the 6 degree model is likely more adaptation to noise.
Among competing hypotheses, the one with the fewest assumptions should be selected – Occam’s Razor
While we addressed the issues of indefinitely sliding off into high complexity hell by using a test data set to get to the neighborhood of test/train error balance, this is only part of the problem. At this point, we hit the crux of the model complexity problem; how much model simplicity and interpretive capability to we want to give up for improved prediction? The linear fit of the first order polynomial is simply the wrong model, but has a very easy interpretation regarding the relationship of y|x; maybe its good enough? On the other hand a 6th degree polynomial is a pretty insanely complex model for most responses and will give you very little in the way of inference. Pick say a 3rd degree polynomial and you give up some predictive accuracy, you do gain the ability to have some insight into that the coefficients mean; even better for a second degree model. The model you chose depends entirely on why you are modeling the data in the first place.
From here, this discussion can drift off into any number of related directions about prediction vs. inference, Bayesian vs. Frequentist, regularization, AIC/BIC/CP, cross-validation, bias vs. variance, lost functions, etc… but that will be for another time. In the mean time, make sure you model is behaving.
Notes:
- The model used to generate the data used above follows as:

- After writing this, I happened to run across another blog discussing overfitting that also used that von Neumann quote to open. I never said I was original.
- This is a overly simplified view of model overfitting, but is intended for a reader at an introductory level of modeling.
- R code for this post is this Gist
